分類分析是機器學習中常見的任務之一,目的是根據已知的標籤資料對新的樣本進行分類。今天,我們將使用 Sklearn 進行分類任務,並以 Iris 資料集為例,建立一個分類模型來預測不同的花卉種類。
分類(Classification)是指根據樣本的特徵將其歸類為某一特定類別。常見的分類演算法包括:
今天,我們將使用 Logistic Regression 來對 Iris 資料集進行花卉分類,並展示如何進行模型訓練、預測與評估。
先在同一個資料夾建立一個叫做sklearn的檔案。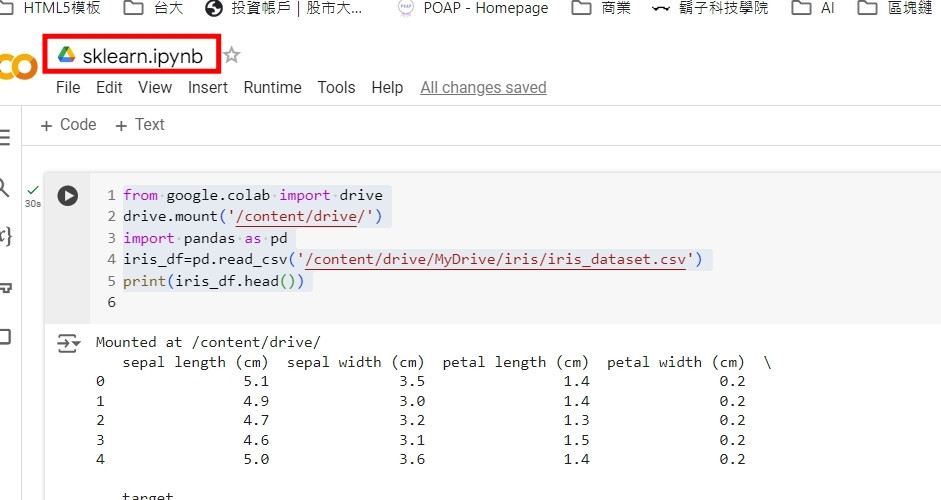
一開始先用這一段程式碼
from google.colab import drive
drive.mount('/content/drive/')
import pandas as pd
iris_df=pd.read_csv('/content/drive/MyDrive/iris/iris_dataset.csv')
print(iris_df.head())
首先,我們需要準備資料集,包括資料的特徵和標籤。
from sklearn.model_selection import train_test_split
# 選取自變數(特徵)
X = iris_df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']]
# 選取目標變數(標籤)
y = iris_df['target']
# 將資料分為訓練集與測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 檢視訓練集和測試集的大小
print(f'訓練集大小:{X_train.shape[0]} 筆')
print(f'測試集大小:{X_test.shape[0]} 筆')
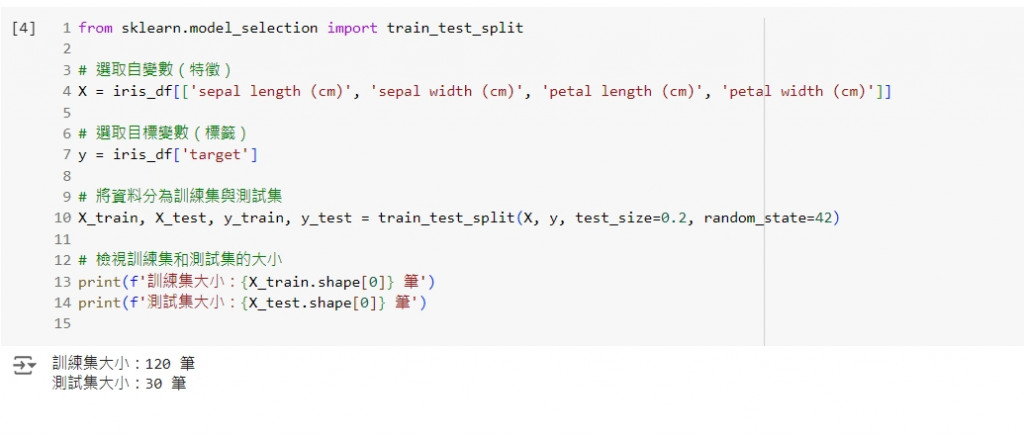
這段程式碼會將 Iris 資料集分為訓練集(80%)和測試集(20%)。
我們將使用邏輯回歸(Logistic Regression)來建立分類模型,並進行模型訓練。
from sklearn.linear_model import LogisticRegression
# 建立邏輯回歸模型
classifier = LogisticRegression(max_iter=200)
# 使用訓練集進行模型訓練
classifier.fit(X_train, y_train)
# 顯示模型的係數與截距
print(f'模型係數:{classifier.coef_}')
print(f'模型截距:{classifier.intercept_}')
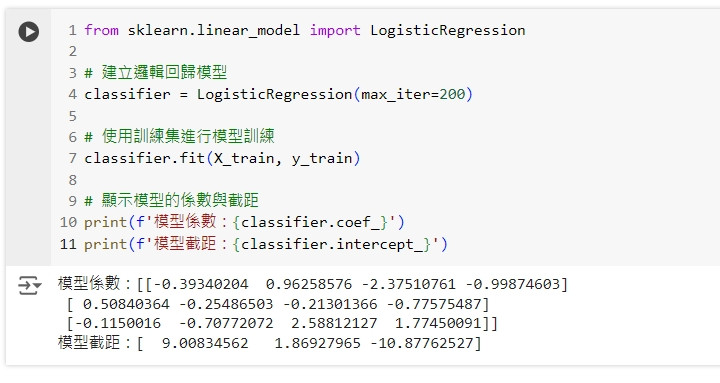
這段程式碼會建立一個邏輯回歸模型,並使用訓練集進行訓練,最後輸出模型的係數和截距。
在模型訓練完成後,我們可以使用測試集進行預測,並評估模型的性能。
# 使用測試集進行預測
y_pred = classifier.predict(X_test)
# 顯示前五筆預測結果
print("實際標籤:", y_test.values[:5])
print("預測標籤:", y_pred[:5])
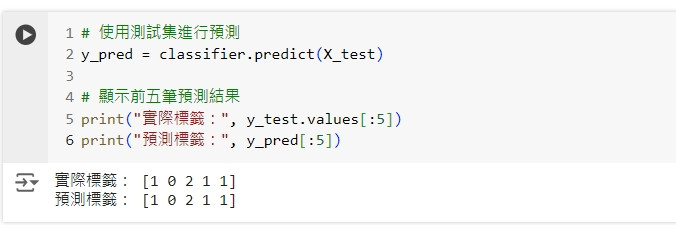
這段程式碼會使用測試集進行預測,並顯示前五筆實際標籤與預測標籤的對比。
我們可以使用混淆矩陣(Confusion Matrix)、準確率(Accuracy)、精確率(Precision)、召回率(Recall)等指標來評估模型的性能。
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
# 計算混淆矩陣
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩陣:")
print(conf_matrix)
# 顯示分類報告
print("\n分類報告:")
print(classification_report(y_test, y_pred))
# 計算準確率
accuracy = accuracy_score(y_test, y_pred)
print(f'準確率:{accuracy:.2f}')
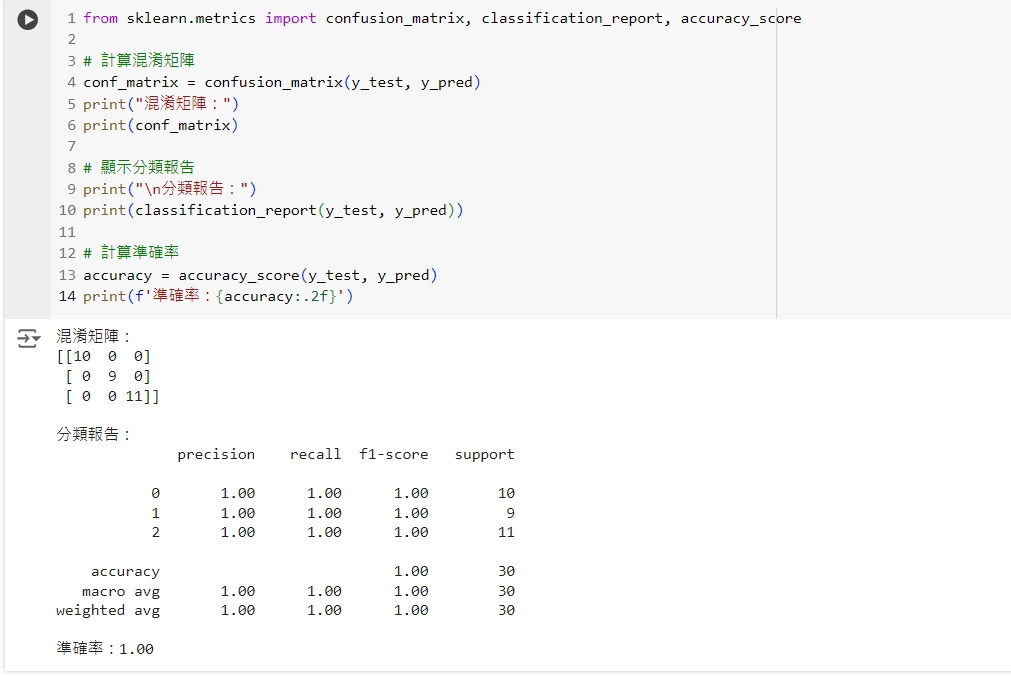
這段程式碼會輸出模型的混淆矩陣和分類報告,包括準確率、精確率、召回率和 F1-score 等指標。
我們可以通過視覺化分類邊界來了解模型的分類效果,這對於只有兩個特徵的情境下尤其有用。
import matplotlib.pyplot as plt
import numpy as np
# 選取兩個特徵進行視覺化
X_vis = iris_df[['sepal length (cm)', 'sepal width (cm)']]
y_vis = y
# 重新分割資料集
X_train_vis, X_test_vis, y_train_vis, y_test_vis = train_test_split(X_vis, y_vis, test_size=0.2, random_state=42)
# 訓練模型
classifier_vis = LogisticRegression(max_iter=200)
classifier_vis.fit(X_train_vis, y_train_vis)
# 建立網格座標進行預測
x_min, x_max = X_vis['sepal length (cm)'].min() - 1, X_vis['sepal length (cm)'].max() + 1
y_min, y_max = X_vis['sepal width (cm)'].min() - 1, X_vis['sepal width (cm)'].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
# 預測分類邊界
Z = classifier_vis.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 繪製分類邊界
plt.contourf(xx, yy, Z, alpha=0.8, cmap='Pastel1')
plt.scatter(X_train_vis['sepal length (cm)'], X_train_vis['sepal width (cm)'], c=y_train_vis, edgecolors='k', marker='o', label='訓練資料')
plt.scatter(X_test_vis['sepal length (cm)'], X_test_vis['sepal width (cm)'], c=y_test_vis, edgecolors='k', marker='x', label='測試資料')
plt.title('花萼長度與寬度的分類邊界')
plt.xlabel('花萼長度 (cm)')
plt.ylabel('花萼寬度 (cm)')
plt.legend()
plt.show()
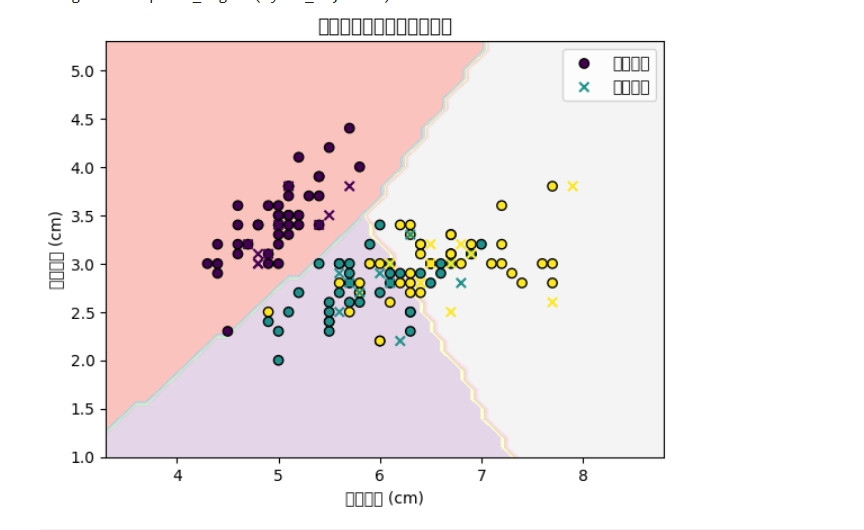
這段程式碼會根據花萼長度與寬度繪製分類邊界,並將訓練資料與測試資料疊加在圖中,幫助我們了解模型的分類效果。
除了邏輯回歸外,Sklearn 還提供了多種分類模型,例如決策樹、隨機森林、支持向量機等。我們可以輕鬆地替換不同的分類器來進行比較。
from sklearn.tree import DecisionTreeClassifier
# 建立決策樹分類器
decision_tree = DecisionTreeClassifier()
# 訓練模型
decision_tree.fit(X_train, y_train)
# 預測與評估
y_pred_tree = decision_tree.predict(X_test)
print("決策樹模型的準確率:", accuracy_score(y_test, y_pred_tree))
這段程式碼使用決策樹進行分類,並計算其準確率。我們可以用相同的方式測試其他分類器。
今天我們學習了如何使用 Sklearn 進行分類分析,包括:


 iThome鐵人賽
iThome鐵人賽